The Challenge
The sinking of the Titanic is one of the most infamous shipwrecks in history.
On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.
While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
In this challenge, we ask you to build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
这个是kaggle上的一个基础项目,目的是探测泰坦尼克号上的人员的生存概率,项目地址:https://www.kaggle.com/c/titanic
网上基于这个项目其实可以找到各种各样的解决方案,我也尝试了不同的做法。但是实际的效果并不是十分好,个人尝试最好的成绩是0.78468,一次是基于深度神经网络,另外一次就是基于当前的随机森林的模型。


另外还可以看到一系列score为1的提交,这些不知道是怎么做到的,真是太tm牛了~~
至于数据的解释可以看下面的表格:
| Variable | Definition | Key |
|---|---|---|
| survival | 生存状态 | 0 = 死亡,1 = 生还 |
| pclass | 船票等级 | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | 性别 | |
| Age | 年龄 | |
| sibsp | 兄弟姐妹/配偶也在船上的数量 | |
| parch | 父母 子女数量也在船上的数量 | |
| ticket | 船票号码 | |
| fare | 旅客费用 | |
| cabin | 仓位号码 | |
| embarked | 登船港口 | C = Cherbourg, Q = Queenstown, S = Southampton |
Variable Notes
pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way…
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way…
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
知道了上面的数据定义,那么处理数据也就有方向了,首先加载数据:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
%matplotlib inline
from keras.models import Sequential
from keras.layers import Dense , Dropout , Lambda, Flatten, Activation
from keras.optimizers import Adam ,RMSprop
from sklearn.model_selection import train_test_split
from keras import backend as K
train = pd.read_csv("data/titanic/train.csv")
print(train.shape)
train.head()
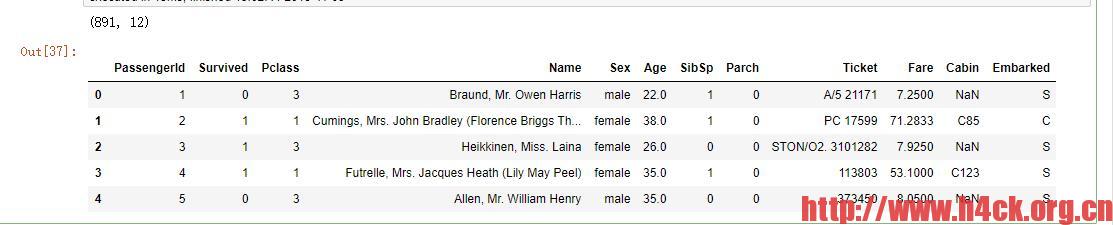
train.info()
train.describe()


# 加载测试数据
test= pd.read_csv("data/titanic/test.csv")
print(test.shape)
test.head()

# 对年龄进行分段处理
def simplify_ages(df):
df.Age = df.Age.fillna(-0.5)
bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior']
categories = pd.cut(df.Age, bins, labels=group_names)
df.Age = categories
return df
# 对家庭成员数量进行分析 以及是否独自乘船
def family_size(df):
df['family_size'] = df['SibSp'] + df['Parch'] + 1
df['is_alone'] = df.family_size.apply(lambda x: 0 if x==1 else 1)
return df
# 对仓位进行处理
def simplify_cabins(df):
df.Cabin = df.Cabin.fillna('N')
df.Cabin = df.Cabin.apply(lambda x: x[0])
return df
# 对费用进行分析 按照费用等级进行分段
def simplify_fares(df):
df.Fare = df.Fare.fillna(-0.5)
bins = (-1, 0, 8, 15, 31, 1000)
group_names = ['Unknown', '1_quartile', '2_quartile', '3_quartile', '4_quartile']
categories = pd.cut(df.Fare, bins, labels=group_names)
df.Fare = categories
return df
# 对游客姓名进行处理分析
def format_name(df):
df['Lname'] = df.Name.apply(lambda x: x.split(' ')[0])
df['NamePrefix'] = df.Name.apply(lambda x: x.split(' ')[1])
return df
# 处理登船港口
def convert_embmarked(df):
df =pd.get_dummies(data=df,columns=['Embarked'])
return df
# 去掉无效信息 姓名 和船票号码对于生存影响不大
def drop_features(df):
#return df.drop(['Ticket', 'Name', 'Embarked'], axis=1)
df = df.drop(['Ticket'], axis =1)
df = df.drop(['Name'], axis=1)
# df = df.drop(['Embarked'], axis =1)
return df
# 对所有的数据进行统一处理
def transform_features(df):
df = simplify_ages(df)
df = family_size(df)
df = simplify_cabins(df)
df = simplify_fares(df)
df = format_name(df)
df = convert_embmarked(df)
df = drop_features(df)
return df
data_train = transform_features(train)
data_test = transform_features(test)
data_train.head()

# 对字符串变量进行编码
from sklearn import preprocessing
def encode_features(df_train, df_test):
features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
df_combined = pd.concat([df_train[features], df_test[features]])
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df_combined[feature])
df_train[feature] = le.transform(df_train[feature])
df_test[feature] = le.transform(df_test[feature])
return df_train, df_test
data_train, data_test = encode_features(data_train, data_test)
data_train.head()

from sklearn.model_selection import train_test_split
# 去掉无关数据
X_all = data_train.drop(['Survived', 'PassengerId'], axis=1)
y_all = data_train['Survived']
# 将数据集进行拆分 80%用于训练,剩余的用于校验
num_test = 0.20
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=num_test, random_state=23)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, accuracy_score
from sklearn.model_selection import GridSearchCV
# 随机森林
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
#history=model.fit(X_all, y_all)
history=model.fit(X_train, y_train)
data_test = data_test.drop(['PassengerId'], axis=1)
predictions = model.predict(data_test)
# list all data in history
print(history)
RF_predictions = model.predict(X_test)
score = accuracy_score(y_test ,RF_predictions)
print(score)

from sklearn.model_selection import KFold
# 通过kfold进行交叉验证
def run_kfold(clf):
kf = KFold(10)
outcomes = []
fold = 0
fprs, tprs, scores = [], [], []
for train_index, test_index in kf.split(X_all):
fold += 1
X_train, X_test = X_all.values[train_index], X_all.values[test_index]
y_train, y_test = y_all.values[train_index], y_all.values[test_index]
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
outcomes.append(accuracy)
print("Fold {0} accuracy: {1}".format(fold, accuracy))
mean_outcome = np.mean(outcomes)
print("Mean Accuracy: {0}".format(mean_outcome))
return outcomes
outcomes = run_kfold(model)
pd.DataFrame(outcomes, columns=['AUC Train'])

plt.plot(outcomes)
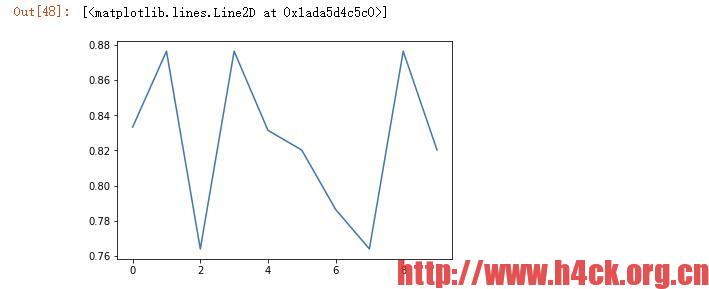
由于数据集较小,因而在交叉验证的过程中精确度并不会有太大的提高,基本是属于震荡状态。
output = pd.DataFrame({'PassengerId': test.PassengerId, 'Survived': predictions})
output.to_csv('forest.csv', index=False)
最后保存文件就ok了。
另外还可以训练多层感知器来做同样的事情。
model = Sequential()
init = 'uniform'
optimizer = 'Adam'
model.add(Dense(16, input_dim=X_train.shape[1], kernel_initializer=init, activation='relu'))
model.add(Dense(8, kernel_initializer=init, activation='relu'))
model.add(Dense(4, kernel_initializer=init, activation='relu'))
model.add(Dense(1, kernel_initializer=init, activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history=model.fit(X_all.as_matrix(), y_all.as_matrix(), epochs=600, verbose=2)

def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel('train')
plt.xlabel('Epoch')
plt.legend(['loss', 'accuracy'], loc='center right')
plt.show()
show_train_history(history, 'loss', 'accuracy')

同样训练不会有太大的准确度提升。
prediction =model.predict(data_test.as_matrix())
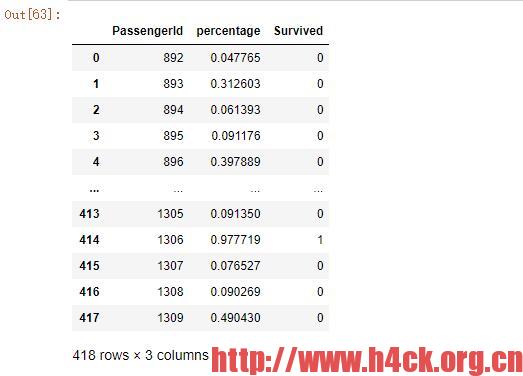
submission = pd.DataFrame({
'PassengerId': test['PassengerId'],
'percentage': prediction[:,0],
})
# list to series
se = pd.Series(prediction.tolist())
series = []
# 将概率转换为生存状态
for val in submission.percentage:
if val >= 0.5:
series.append(1)
else:
series.append(0)
submission['Survived'] = series
submission
submission= submission.drop(['percentage'], axis=1)
submission.to_csv('p.csv', index=False, header=True)
参考链接:
https://blog.goodaudience.com/introduction-to-random-forest-algorithm-with-python-9efd1d8f0157
http://tensorflowkeras.blogspot.com/2017/09/kerasdeep-learning_32.html